tl;dr - We’ve made docs calculate and load up to 68% faster, and decreased the file size of the largest Coda docs by as much as 85%. That means faster, more performant docs that you can access to do even more via our API.
Sometimes making software faster means finding opportunities to optimize code and storage. Sometimes it means re-writing your foundational code entirely. The past few weeks at Coda, it’s meant both. Read on to learn how our team has been hard at work making Coda even more performant for you.
Continuing to optimize our code
In past updates, we’ve shared how we optimized storage of column data and facilitated progressive loading of docs to help you access your doc content more quickly. Since then we’ve closed out more than 20 additional work items to do everything from making sure to calculate aggregate values only when they’re needed to optimizing how we reflect sorting and row updates, unlocking additional performance improvements for your docs.
These changes benefit all docs, but are especially noticeable in large docs. Here’s how our improvements have impacted tables with 10,000+ rows:
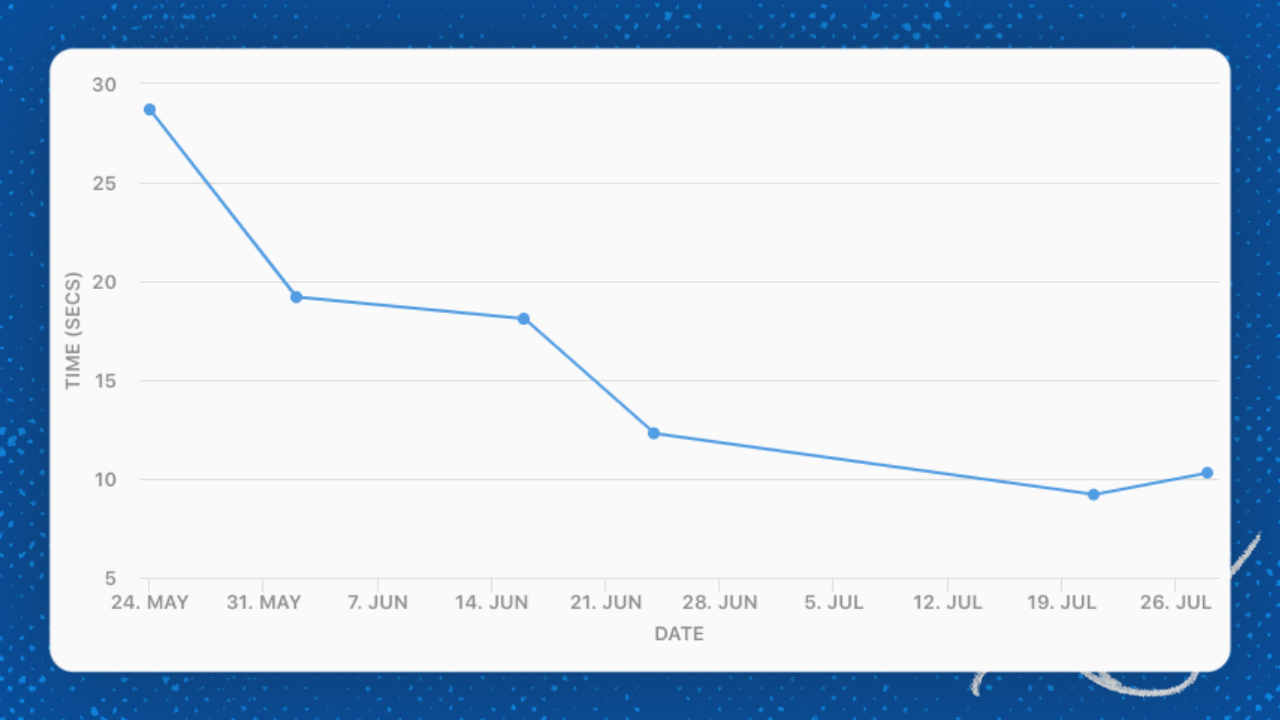
Average time to load 10,000 rows
In other words, large docs can load up to 68% faster than before!
Rewriting our JSON snapshots
It’s not glamorous work, but someone has to do it. And, as CTO at Coda, it’s my honor to work alongside our talented team to do everything we can to make your docs more performant.
While looking for opportunities to improve performance, we noticed that loading Coda docs out of JSON means the entire JSON snapshot has to be loaded before you can view anything in Coda. By way of background, JSON (JavaScript Object Notation) is a format for storing & transporting data, most commonly used when data is sent from a server to a webpage. Because JSON is “human readable,” it is more verbose and takes more to communicate to our human brains than it would if just communicating computer-to-computer.
So, I went into the Matrix . . . just kidding. But I did rewrite our snapshotting to create our own binary file format, which more efficiently stores table data, allowing for quicker reads and writes. This, in turn, allows for more efficient sharding—which is a way of partitioning data in a database for efficiency by not calling every single bit of data unless it is needed for an operation or visualization.
As a result, individual table cells enjoy much smaller encoding so that we can process data faster (and you can make more robust API calls now that your docs are “smaller.”)
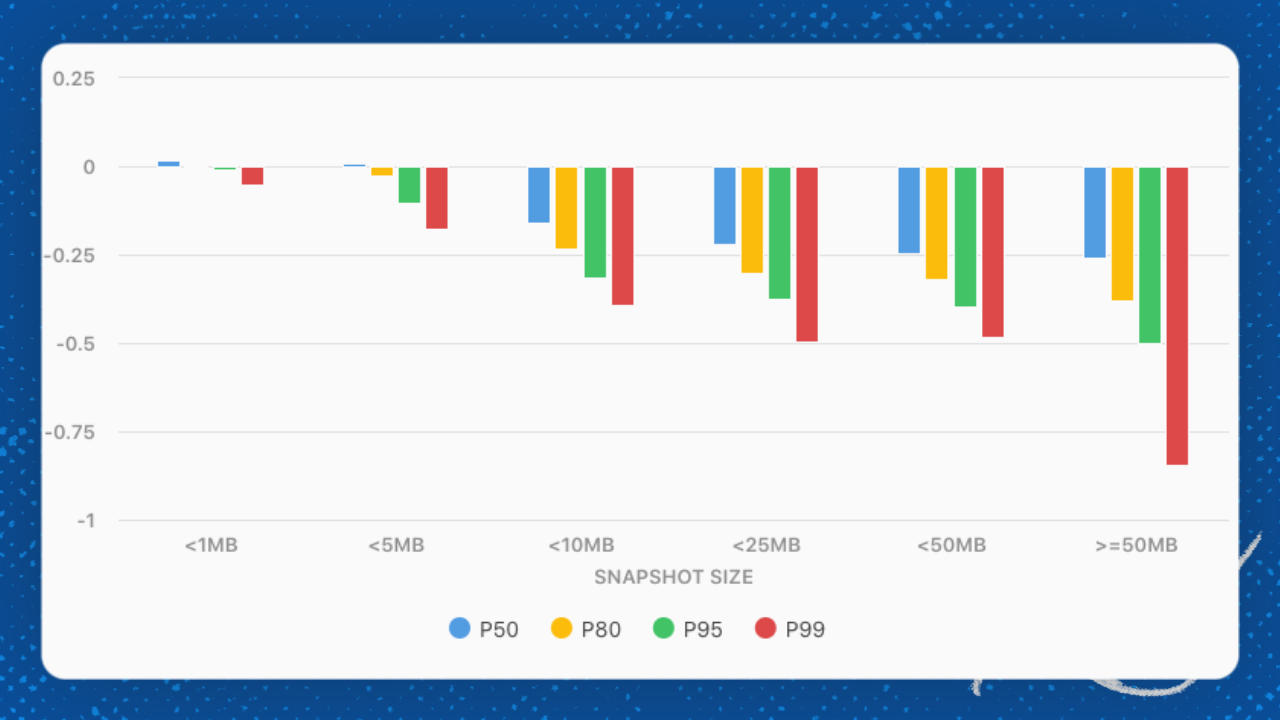
Median percentage reduction in uncompressed doc snapshot size by previous doc size
This is just the latest in our continued work to make Coda more performant for our valued Maker community. As a reminder, if there’s an area of Coda you think could be more performant, please share your feedback with us via this form.
We can’t wait to see what you Coda—even more quickly than ever before.
 Thank you for focusing on performance
Thank you for focusing on performance 
 THE OBSTACLE IS THE PATH!
THE OBSTACLE IS THE PATH! 








