My entry info Coda’s Showcase > AI at Work Challenge - an AI Process Manager - won the Big Splash category (along with @Bill_French’s Promptology). The doc is a combination knowledge base and work management system, allowing you to:
- manage your org’s processes - how you do your work - as a single source of truth
- generate new processes and the steps to complete them
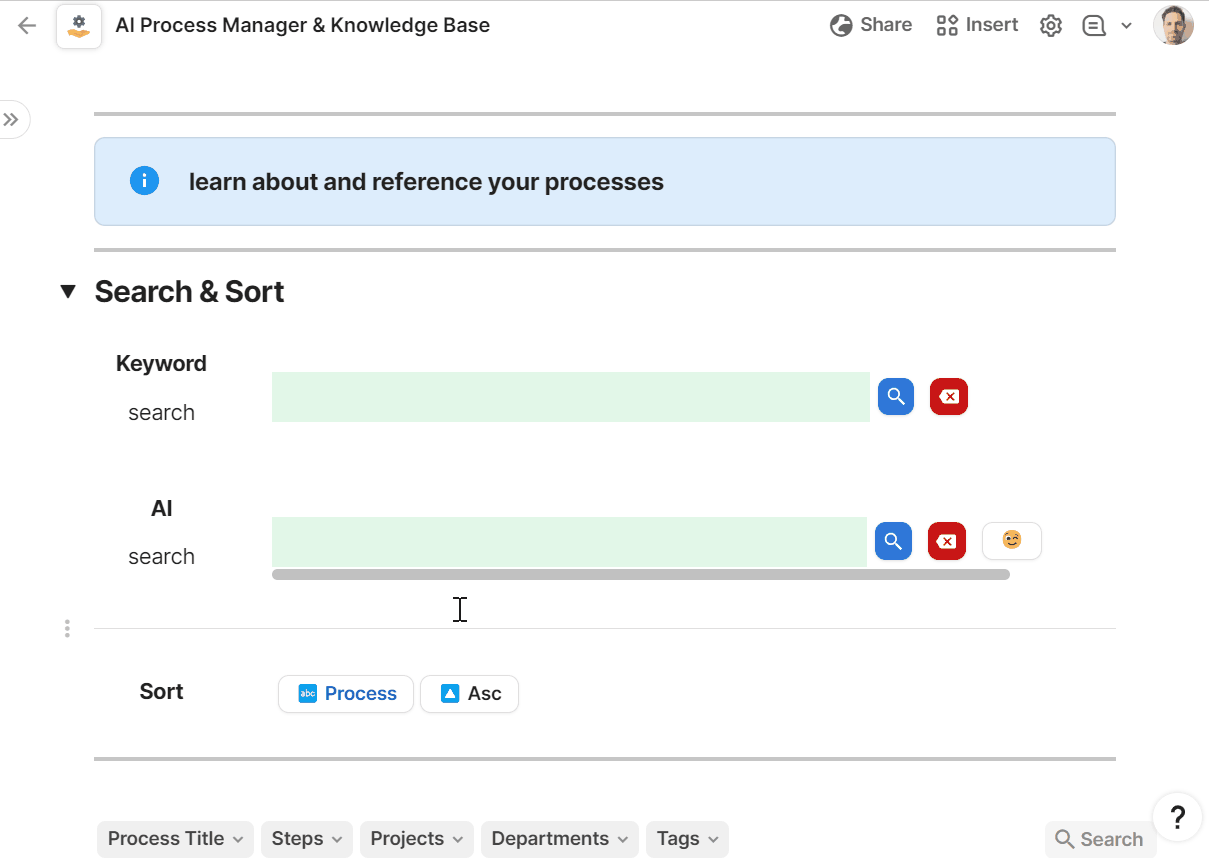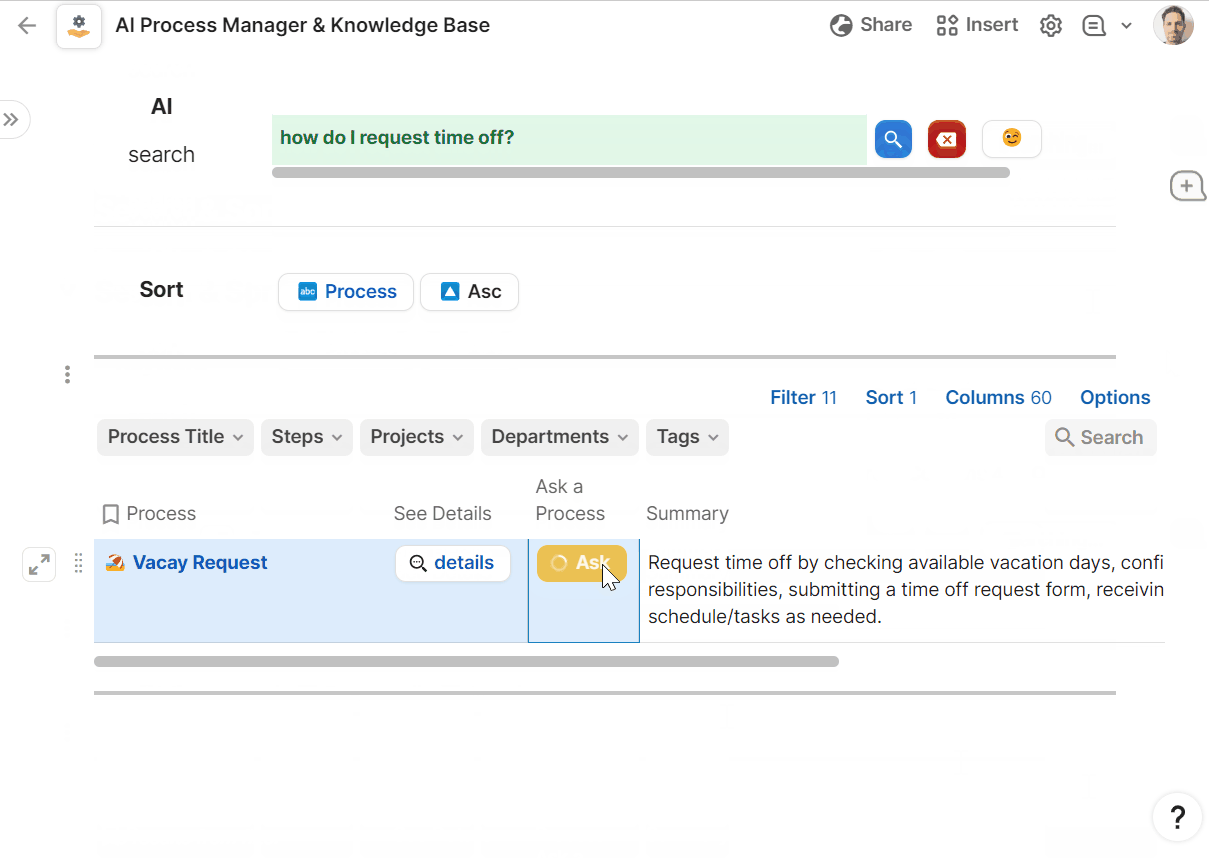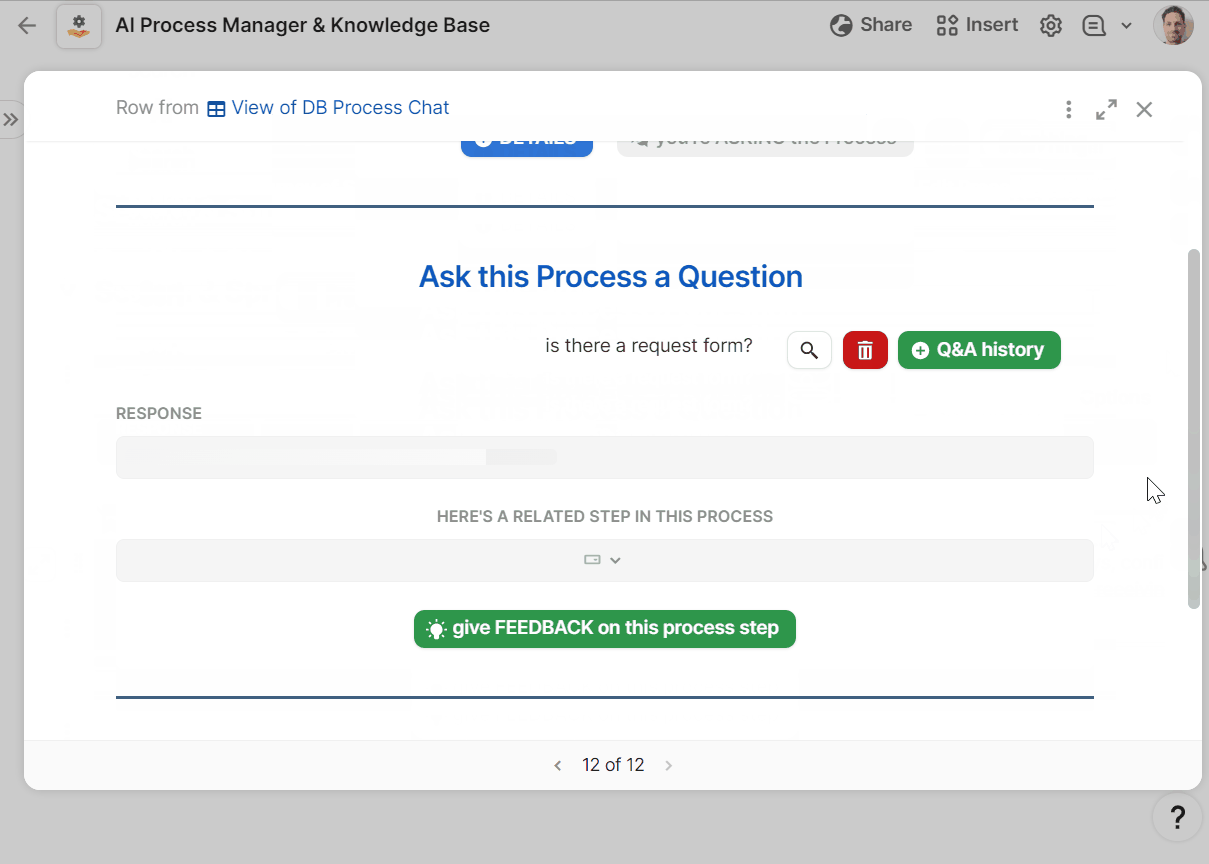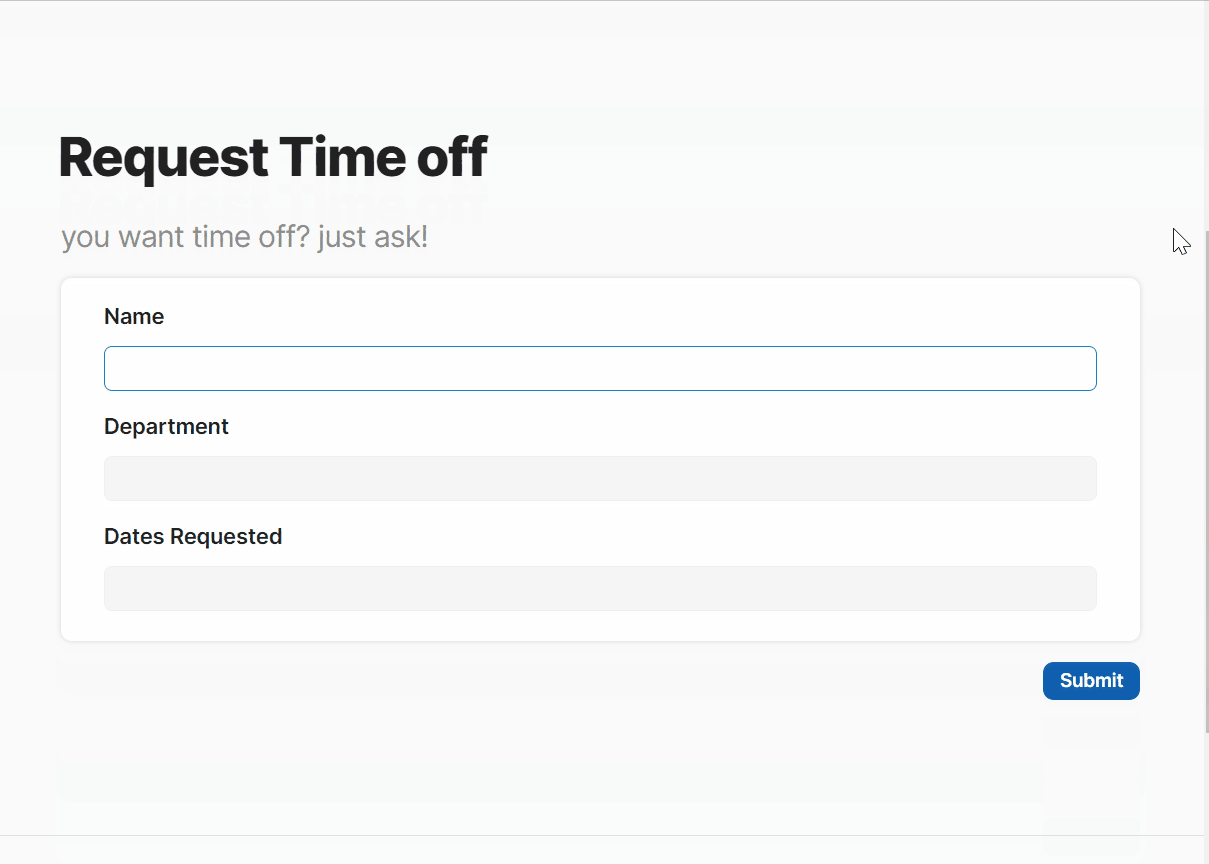
- ask your work a question in plain language
- run processes as sets of tasks
- log feedback and continuously improve your work
So the Showcase > AI at Work Challenge was hugely beneficial to me, helping me explore how Ai can augment human performance and simplify work. Here are five things I learned through the building of this tool.
1. Navigating short development windows
I built this tool across three weeks of spare time. That’s a narrow window for me. I knew early on that I didn’t want to create a one or two page template - I wanted a full working process manager app. This meant being ruthless about understanding my customers (workers and org process owners), the features I would include, and the level of polish I would apply.
To guide the build, I started the doc with a single “thoughts” page, where I wrote out the steps in the user journey - their workflows. I then added notes about the tables I’d need to bring those workflows to life. These notes were critical in helping me stay focused.
I also added a kanban table for feature building, where I added and sorted ideas as I was building. This helped me log those ideas without immediately actioning them. I would check-in periodically and rank the features on their usefulness to the customer. I used this feature board to inform my next steps.
What I missed was user testing time. I didn’t allocate enough time to getting the tool in front of people, getting their perspective on the tool’s workflows, and ultimately making it more user-friendly.
2. The Art of Prompt Engineering
I spent more time than expected writing my AI prompts to avoid AI hallucinations and similarly destructive artefacts. As a source of truth for the organization, I needed the AI to answer questions about processes truthfully, for example, stating that a certain resource does not exist in the library, then providing some helpful advice anyway. I found that adding instructions to the prompt like “If the answer isn’t in the background information, it is critical that you state this in your response, then do your best to provide an answer anyway.” did the trick.

The other key here was incorporating organization-specific information into the prompt to situate the AI’s responses. I was finding responses were too variable, so I gave the user a place to record some basic information about the org and its purpose. Referencing this throughout the doc’s prompts helped the AI provide better contextual information.
3. Overcoming API Limitations
I quickly hit the ceiling on prompt size when including background info on the organization, a process, its steps, and any resources included therein. Word limits for prompts were maybe around the 3,000 mark. So I used compose columns to create unique summaries for each AI prompt, selecting the most relevant information to feed the AI to produce the desired result.
4. Balancing Costs & Benefits
Throughout the build, I gave too little thought to how much this tool will cost to use once Coda flips the monetization switch on AI. Right now Coda AI is free, making Coda probably the best AI dev tool around. But at some point, I expect to start paying a per-token or monthly premium to use AI. This means a v2 process manager (and any docs you’re building that leverage AI) will need to give close consideration to any columns set to auto-update. Instead, I’ve begun to add AI Assistant Refresh buttons to most of my builds. It requires an extra click from the user, but will maintain a strong value proposition for users even with future pricing models.

5. Trust and AI
Ai is powerful but it’s not perfect. It can also give such a strong impression of authority that people turn off their critical mind. Imagine the risk inherent in a worker asking how their long-term disability benefits work, getting some AI hallucination, and putting their full belief in it! Users need to be reminded that AI responses are suggestions and require some deeper consideration rather than blind acceptance. The trick here is that often only someone with expertise in the issue will be able to see where the AI has gone off track. Large disclaimers should be put in front of the user, telling them to use their judgement before acting on the recommendation of the AI. Also, more work is required before AI is allowed to make changes directly, rather than providing recommendations and having a human do the work.
If you’re interested in hearing more about this use case, my build, and my lessons learned, I’ll be presenting the doc as a case study at the Innovations in Knowledge Organization (IKO) conference this September 12 at 9pm EST. It’s a free virtual conference, hosted in Singapore, and I’ll be presenting alongside some other really interesting AI and knowledge-based projects.
Thanks for reading, and you can copy the AI Process Manager doc for free here.