On a recent Zoom session with our AI team, I watched as they struggled to find a specific Coda document. It troubled me because workers tend to spend about a fifth of their day groping for information to get things done. One report says this number is much higher.
In any case, the torture I witnessed inspired me to create a search engine and what better place to build it than Coda itself. With that, I created our search engine using the core architecture of Lucene to build an inverted index using a number of really simple tactics.
The outcome was warmly welcomed. It has a variety of features including term exclusions like searching for social, but not media.
social -media
It’s also a personalized app so multiple users can search without colliding. And it supports a scoring algorithm straight from Lucene. It doesn’t yet handle full-text indexation of all content, but I have a prototype that does this - a bit more complex to get at the body texts of a document as you all know. However, just by indexing and tokenizing document names, pages, users, folders - we have essentially solved the riddle of rapid findability in Coda.
What does your team do to increase findability in your organization?
Thanks! I’ll share the general architecture when I have more cycles to document it. I’m really curious how other orgs mitigate the hidden pools of information that Coda seems to be good at creating.
I am busy reading the article you referenced above.
SAP implementations have a very similar problem, where you have large numbers of people that are basically involved in a two way knowledge transfer.
My proposed solution to that, is to put everything into a single Coda doc. in the end it will replace several hundred spreadsheets, and maybe a hundred or so word processing documents. (I do hope that Coda can handle the volumes… ) Coda not only enables the replacement of those freestanding documents, but integrating them with each other to provide vastly better information. And then integrate that with to-do lists.
And because everything is in the same doc, status reports simply become summaries of the various documents and the to-do list.
That’s a lot to unpack (literally). On the chance that you’re not pulling my leg, even if that approach were practical for typical browser/computer memories, there are issues like …
Extremely granular permissions if used by teams
Burdens the client and server to paginate requests
Doesn’t eliminate search requirements that can be satisfied only by an inverted index such as wildcard queries, exclusions, and boost relevance based on terms in the document name, subtitle, H1, H2, H3, etc…
I’m not feeling it.
Search and findability is definitely in a league of its own. Simple questions like -
Should the discovery of a document titled “2023 Layoffs” be considered a security breach even if you don’t have the rights to view the document?
The tool that I am working on is a very specific, and a VERY structured use-case.
And I am completely serious. (Although I have been known to think a little bit too big from time to time… )
The spreadsheets come in two categories, master data (Customers/ Vendors/ Materials/ Boms) and configuration data (Org structures, goods movement types, mappings between GL accounts and goods movements, etc, etc). The word processing docs are functional descriptions of various parts of the system, e.g. Sales via Vending Machines, Direct Sales via Amazon, or Product Cost Planning. Also word docs to describe gaps in the system that needs to be filled through enhancements, reports , forms etc.
If it does not fit into a single doc, it would need some nimble thinking to split into say Financial Accounting, Sales, Procurement areas, and then use cross docs for the integration…
Here is what I have so far, in case you are intrigued. I have the page structure for the 174 Finance config tables, but not the 174 tables yet - Sounds like I should get to that sooner rather than later…
There are some videos to explain the basics, but at double speed, it will take more than an hour.
Very specifically geared to the process of implementing the system. No consulting house HR, no consulting house Financial info - the info SHOULD be available to all.
No need to rent. In fact, if you succeed at crafting a unified document, it’s far easier to build a Lucene-like search index in a single Pack with no servers needed. The index itself might be best managed as a collection of indices of pages, tables, texts, images, etc. Might actually be pretty simple to craft.
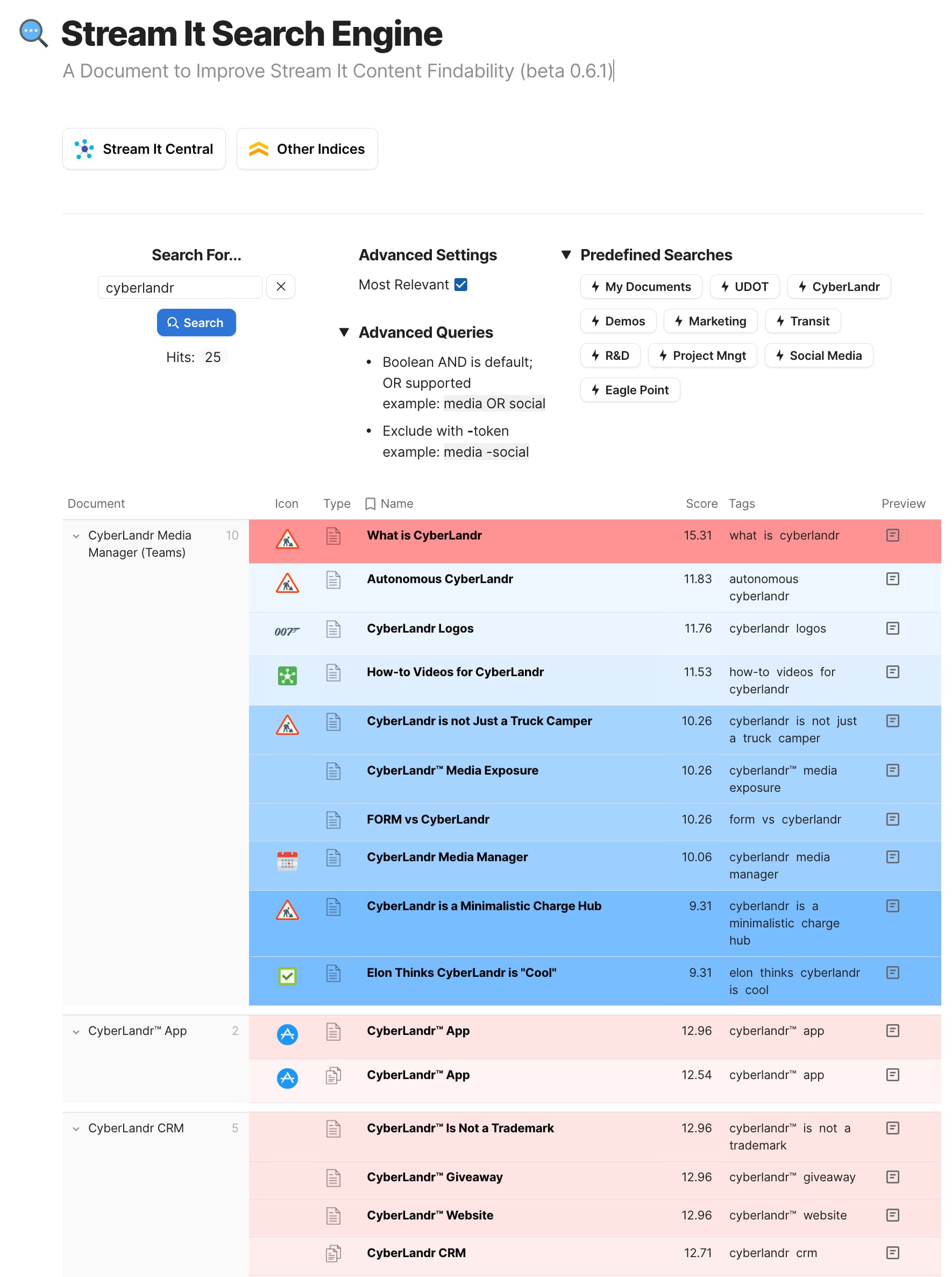
Just having a search interface that surfaces pages with page icons like this would be a big leap in findability. Our team struggles with findability, but often not because Coda search can’t find the page people are looking for at all, but because when it does find the page, it’s not clear from the results that it’s succeeded.
I wrote an article about the problems with Coda search results earlier this year, but the images below summarize why our team often can’t find things: they do a search that should find a page, but the results look like the page wasn’t found.
Yep - same here. They complained about this exact issue. So, when I built the search system I made certain that there were visual queues for document, page, and table “types”. This also makes it easy to create user-selectable filters - check box for tables only, etc.
Some users have also branched the app to apply different color schemes for results. One uses red for tables, blue for documents, and yellow for pages. The results relevance is still the sort order, so they’re pretty happy with the agility.
I am intrigued by you including tables in your searches. I thought I was being clever by creating “How to” databases for various parts of my business. I have found Coda’s search feature handy to find things so I thought it would be faster to search for the “How to” I needed at the time instead of wading through Docs and Pages to where I knew it was and then searching the table for the right row of content. I discovered that Coda’s search function doesn’t include text in tables so it didn’t work. What you’re doing sounds VERY POWERFUL.
Yeah, there are many limiting nuances, but to be clear, my approach doesn’t index content in tables either. This was an initial design choice made not because I couldn’t, but because it does require some pretty big index files depending on the table content. I will eventually add the rows and certain fields to the index, but until then, I index the table name and the parent (page) and the parent (document). I do capture the number of rows and a few other general attributes.
But our users seem quite thrilled with the ability to instantly locate a table based on terms that match or are similar to the table names and then happily use the in-table search feature.
Fuzzy search is on the agenda and probably an ideal feature for table data search. It would be pretty helpful to search for QA and see quality assurance results in the hit list. Or, search for Pittsburgh to find Pittsburg.
Thanks for the clarification, Bill. I’m not surprised indexing content in tables is complicated. In the meantime, I am revising the way I build/use the table so that it still serves me well and my team too.