Background
I’m creating a Coda doc for software development tracking (think Jira), and I’m trying to work out how best to model the following entities:
In Jira, these are treated as issue types. This means there is one big table - the issues table - and issue type (epic, story, task, bug) is an attribute of an issue (in the form of a lookup to the issue types table).
Question
What are the pros and cons of:
- Replicating the Jira schema (
issue table and issue type table) in Coda, vs
- Creating separate tables for each entity (epic, story, task, bug)?
My thoughts
- I feel like it will be easier to manage everything with separate tables (option 2) - otherwise there’s going to be lots of self-referencing in lookups.
- I can’t see a need for displaying all records (across epics, stories, tasks and bugs) in one big table. Nor reporting across them all.
Any suggestions most appreciated  .
.
Following - I’m building a similar doc right now, BUT will need reporting across all of them as well tracking time in status ideally. Each data model is a bit different, so would like them to be in separate tables vs one with many columns that are issue type specific.
Maybe a compromise could be adding a lookup from type -> type / type-specific-columns type table?
Hi @Andrew_Davis1,
I think this is and will always be an open discussion.
If I can put my two cents on it, I’d just say that data modelling should take into consideration the overall data lifecycle.
I use to simplify it by dividing into three main data perspectives:
-
Semantic: “what is what”
-
Interactive: “who, when and how is “actively” using it”
-
Informative: “what (aggregated) information I need to extract” (what @Philip_Johnson1 also pointed out)
Many times (too often) we tend to rely on the first one only.
Very rarely though the three ones can converge to the perfect solution.
The very good thing in Coda is that you can design the three of them within the same application.
In your example I’d assume the Epic and Story might be fed and maintained by similar people and they need specific interfaces and solutions for that purpose only.
Similarly, Task and Bug can rely on the same premises and need to keep track of a good deal of similar columns.
So, maybe it could even be an hybrid solution with a Narrative or Vision table with a self referential hierarchy (Epic and Story) and Activity (where Task and Bug are just different types and there are no hierarchies).
Again, it’s just a suggestion: don’t take it as a solution unless it fits the full usage needs.
Trying to describe the whole process would help to understand where to draw boundaries among the aforementioned perspectives and what to prioritise.
As per the "single Issue" concept, I’m not against it but only if we had a polymorphic data structure.
(have a look at this post: Extension Tables)
Meaning we could group together only the common features.
But we don’t have it (and it’s not necessarily a bad thing) and maybe having an “holistic” table (all the columns for all the types) could even work.
I hope I just didn’t create more confusion than clarity
Cheers!
3 Likes
Thanks @Philip_Johnson1. This approach makes sense. My main concern is that it might not provide an intuitive interface for people trying to enter data.
@Federico_Stefanato thanks for the 3 perspectives for deciding on the right schema. That’s very useful.
I’d now like to try out the self-referential hierarchy for Epic and Story.
Question: how do I actually implement it?
I created a lookup column from issue to issue, but I think I’m doing something wrong. I get strange behaviour when:
- Trying to display child issues (stories) on the parent issue (epic) detail layout.
- Trying to configure a button on that same layout which creates a new story from the epic and links the story to that epic (
thisrow doesn’t seem to do it).
Thanks
Scratch that. I’ve now worked it out after checking out Mind map (tree chart) implementation (!) by @Paul_Danyliuk. Thanks Paul 
However, I’m now wondering if I’ve encountered a UI/layout limitation with using the single table?!?
Separate tables
When I had each entity in its own table, I was able create the following layout for a story record:
Sorry it’s so small, but I wanted to show the fact that there are separate buttons and sub-tables for scenarios (one entity) and tasks (another entity) visible in the one story record.
One table
If I use one table for all entities, I believe my only option is to have one sub-table with all the entities (potentially grouped by type):
If so, going back to @Federico_Stefanato’s classifications, I now feel that:
- From an interactive perspective, separate tables for each entity would be better
- From a semantic and informative perspective, I would prefer to have one table for all the entities
Have I missed anything?
Hi @Andrew_Davis1
you can in fact reach the very same solution also with a single table (having perhaps different filtered views according ti their types).
If you could share your document (or its data-insensitive copy), it would be easier to dig a bit more into it.
As said, the “perfect” solution will be a compromise; therefore, not perfect by definition  .
.
Hi @Federico_Stefanato
I think I might have actually worked it out - thanks to you and all the Coda Community posts
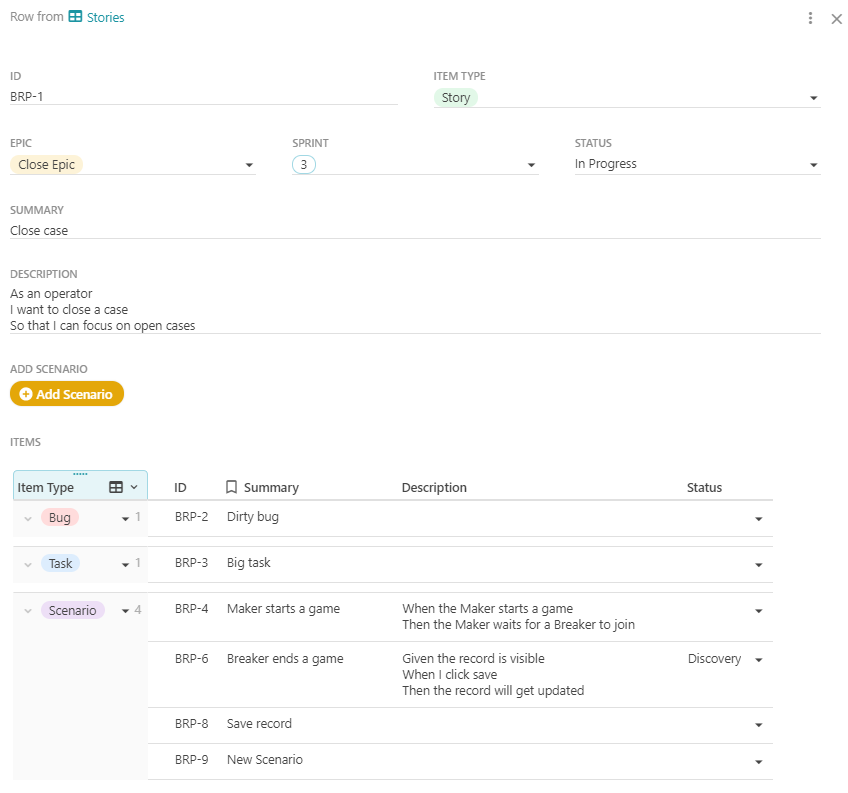
I’ve created two source tables:
- Issue
- Issue Type
All of the epics, stories, scenarios, bugs, and tasks are issues, each with its own issue type.
I’ve then created views with filters for each issue type, as per the below.
Is that what you had in mind?
Hi @Andrew_Davis1
sorry for the delayed answer.
Yes: I think you perfectly implemented it.
Just give it some time to see if this covers all your - and all stakeholders’ - needs.
Let me know if you need any further support/opinion: I believe you have everything already pretty clear.
Cheers!
1 Like