I’m trying to figure out how to set X to have dynamic values based on the 2 values of selected warehouse(saved as a variable named “lookup1”) and product code(saved as a variable named “lookup2”).
This can be achieved using HLOOKUP in excel. VLOOKUP in coda is just adding a lookup column and you’re done. But I’m trying to do it where column need to be selected/created dynamically. Lookups give me rows of different table as values but not columns.
I’ve tried following things:-
Lookup function - gives error as lookup2 is considered a text and can’t be passed as a column parameter for lookup function (also tried combining with the toText() function)
Nth value from product column in inventory table- Using find to get the position of warehouse value in inventory and then trying to use the nth on invetory.lookup2 list. same error lookup2 can’t be used as a column.
Maybe I’m just missing something very basic here.
Thanks for any help you can provide.
You’re modelling your data wrong. Unlike Excel, in Coda rows and columns have strictly specific meanings: rows are records and columns are properties. Each column describes a measure or a dimension.
A measure is a value of a record:
Number of sales
Number of items available
Restock price etc.
and dimensions are different “groupings” of such values that belong on different planes:
Warehouses and Products are different dimensions. “Cola”, “Fiji Water”, and “Gatorade” are values along the dimension of Products, and “Warehouse 1” is a value along the dimension of Warehouses.
Manufacturers and Products are on the same dimension, just a different depth of detail. Both “Cola”, “Sprite”, and “Fanta” Products belong to a more general group of “The Coca Cola Company” value on Manufacturers level. But since each smaller group is uniquely linked to a larger one, the latter can be inferred from the former through a lookup link. Hence it’s not a separate dimension.
Then, a row (a record) contains information about a value on each dimension and a measure that describes the state of things at the intersection of that measures. It can have multiple columns per dimension to contain values from different levels of detail along that dimension (e.g. have both Manufacturer and Brand columns) but very often only the most specific one will be an input, and the more aggregate ones will be lookup formulas.
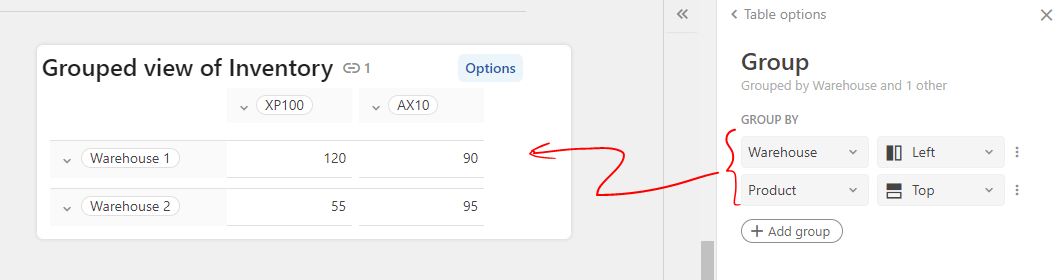
Now take a look at your Inventory table. You implemented it in such way that tells:
Warehouse name is a dimension (correct). There can be zero, one, or more Inventory records for each Warehouse value.
XP100 is a measure — a property of an Inventory row
XP200 is also a measure, a different property of an Inventory row
and so on.
This is incorrect because XP100, XP200 etc are not properties (not separate measures or separate dimensions) — they are values at a common dimension, the dimension of Products. So to model this properly, your Inventory table must look like this:
Thanks @Paul_Danyliuk . Amazing explanation. This is exactly what I was looking for. I was struggling to set products as a reference when I directly made columns with their name. Your approach solves this issue.
Thanks for your help .