I was reading through “Optimizing Formulas” and saw two possible improvements I could make on a slow query:
(A) Atomic Formulas:

( Optimizing slow formulas in your doc | Coda Help Center)
This “Atomic Formula” concept is also mentioned in: ( Strategy three · Good habits: aggregate and optimize (coda.io))


(B) Making sure column output matches column type
I decided to implement in my doc, but had worse, not improved results.
I have a table t_Users. I also have a table t_TimeLog. t_Users has several columns which summarize durations per user from the t_TimeLog table. t_TimeLog has a Start Time, End Time, and calculated f_Duration based on those two datetimes.
The user summary columns look something like:
t_TimeLog.Filter(User = thisRow AND DateTime = AAA).f_Duration.Sum().Round(1)
t_TimeLog.Filter(User = thisRow AND DateTime = BBB).f_Duration.Sum().Round(1)
t_TimeLog.Filter(User = thisRow AND DateTime = CCC).f_Duration.Sum().Round(1)
(1) Because the output is a number, I set the column type of the summaries to Number.
(2) Also, because I reuse “t_TimeLog.Filter(User = thisRow)”, I thought I could pull that out and it could filter the user, and then use the filtered by user result to filter for the different times.
I assumed both of the above would speed up my columns. But they both did the opposite.
In the snapshot below, you can see I labeled “Hrs Worked This Week” by whether I set the column as a Text type or Num type, and labeled by whether I use the Raw unfiltered table to grab the durations, or if I use the shared Filtered by user column.
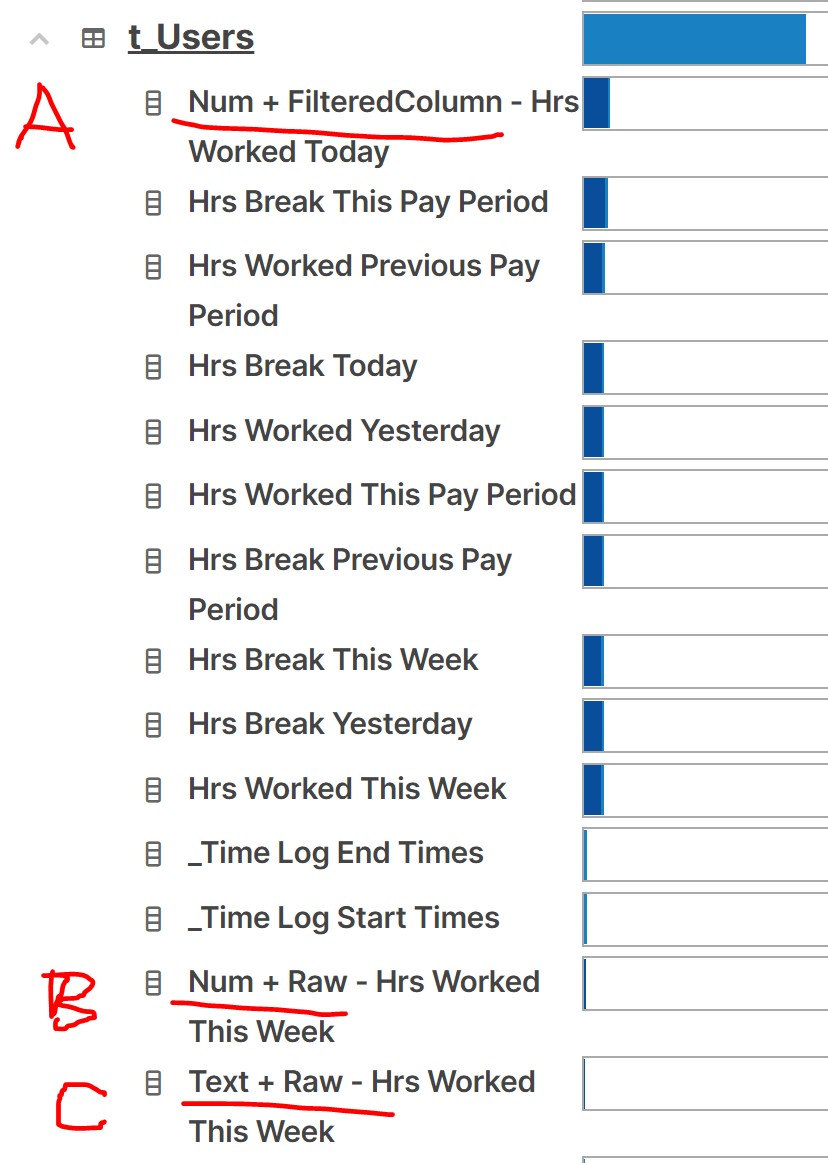
You can see that (C) is fasted, where I used the incorrect Text type, and where I went straight to the original table to filter out user, instead of using the pre filtered column (which I can reuse across the rest of the summary columns, so that each column doens’t need to grab the entire t_TimeLog table, but can just use the prefiltered by thisrow.user column).
Is consolidating the filter this way always a bad idea? And why is using Text for this field faster than using Num?