Hello there 
I want to present a good solution that i’ve prepared to manage my user’s data in my doc.
Warning: You will need cross doc actions for this!
Let’s first understand the use case with a drawing:
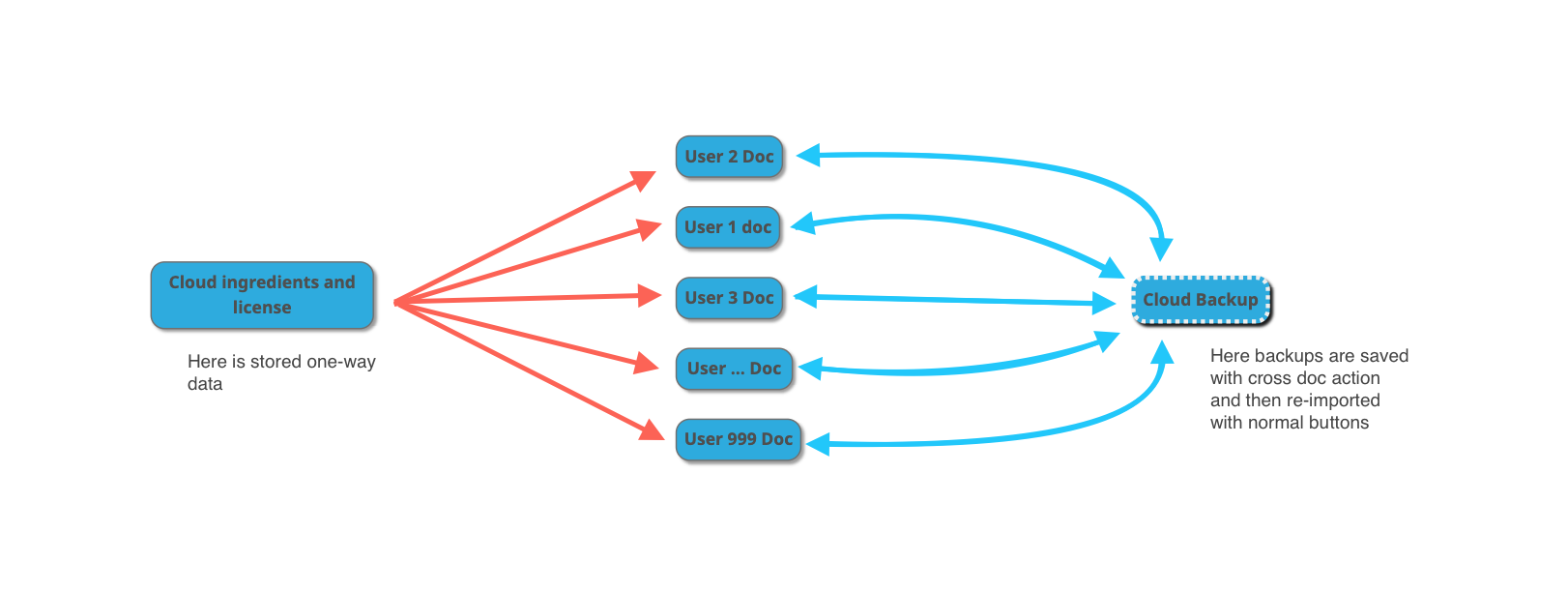
I have all the “client” side that is represented by the central docs, one for every user/organization/community, this is the doc that users use.
Then on the left i have the “one way” “server side” that store data that are needed in “view only” mode, so a normal cross doc here was sufficient (just to bring this as an example)
On the right we have the “Cloud Backup” side, that is just a doc that we are gonna use to store our users backups.
Given the current limitations of cross doc sync i’ve chose to just save all the user data in the “Cloud doc” and to then restore them in bulk later / when needed after a “full reset” of the doc, this is not a live data sync!
In this way i’ve solved also the problem of the “lookup” columns that are not able to find their data anymore. This is solved with a formula that do not simply replace the data in the cell but instead look in the “lookup” origin table the corresponding row and use that one. (more on that later)
Ok, so, now, first moves?
Prepare our data:
- To do this fast i found this way, create a view of the origin table in the origin doc and hide unneeded columns (the one that are calculated or not needed in the backup).
- Do that for every table that needs to be on the backups.
- I’ve added a new “rowId” column using a MD5 formula, this because the normal rowId is not a good reference for multiple docs (every user will have possibly the same rowId), i’m sure that this will slow down doc in some ways, but i wanted to try crypto
 . You can obtain the same result arranging some type of internal code algorithm to generate an unique code
. You can obtain the same result arranging some type of internal code algorithm to generate an unique code 
Set up the Cloud Backup doc!
- Create a new doc and copy in this one all the table you have prepared before (whole table, header of the table should be light blue). You are not interested in the data in it, you just want to keep column name
- Now, delete all the formulas in those columns, you will need text column type in those, with no formulas.
- Give those table a nice name asap . With cross doc the first sync carry the table already formatted as you want it, without need to customize it later!
Now, back in the original doc:
- Import as cross doc the table in the Cloud Backup doc, and make sure that you have set the permission for cross doc profile as “Take actions and view data”. (those passage needs some practice)
- Now, go back in all your tables to backup and create in each of those a new button column, this will be needed to push the data in the Cloud Backup doc, so now configure it to add a new row there and copy all the column data (for many column see the trick later to bulk prepare formulas)
- Configure those according to the normal cross doc action way
- Try them and check if data are in the other doc
Ok! Now we have the export of data that works!
But our data are really messed up, let’s organize them better!
I’ve created a table that store all the backups information, importantly the name of the backup (in my case an user-defined name and a timestamp)
When you are gonna press a button to “create a backup” (that is gonna press all the button made in the previous point, maybe filtering those per-user) a new row in this table will be made, with the backup’s name. you want this there because later you are gonna refer to this to name all of your backup’s data
you will obtain something like this in the origin doc:

That will create something “group-able” in the Cloud Backup, like this:

This for every table needed
Now, i’ve preferred to have a Dashboard view of those backups, in a few you can build a table like this:

That check if the needed table contains data with the same “Backup CODE” as that row.
Ok so now briefly we have covered the “Input phase”, let’s talk about the restore of the data.
Important! It’s a good idea to import those in the same order in which user have input those in.
Create a new “restore” button column in the cross doc table of the backup, this in the origin/client doc.
That button is gonna Add or modify rows (or just add) to the original table, remember to use .filter and not just plain text when you import, you should obtain a long formula that should looks like this:

If you have text, like “1/1/2021” or “John and Clara” is ok to import it in the "blue way"
If you have link to other tables, you have to set up formulas in the “red way”. this to re-create the link between those.
Trick: If you have many columns, you can copy the table from coda and paste it in sheets (lol) and transpose the columns name, then add the needed character like “[” “]” ","ecc, now delete the tabs between datas in a text editor and voilà you have formulas ready for coda with minimal efforts
something like that:

Ok so you’ve set up all the button columns to import those data back at their spot, nice work!
Now, what i’ve done was to create a button back in the table of backups (the upper one) that checks if the backup is present in the cross doc table, and then press all the buttons on the cross doc tables present in the origin doc (always checking if the user is currentuser) restoring the data back in their place
To the final user this is the view:

or, possibly,

There are huge margin for improvements as you can see 
Second trick:
Create a button to “Delete all” in both doc, in the “Cloud Backup” to clean it during testing, and in origin doc to delete all user’s content before importing the backup, it will speed up processes
Ok! That’s it, now you have a fully working import/export on “cloud” feature on your doc,
I’m impressed to say that it really works!
Ah yeah, you’ll need some times to tune it right  it can misbehave in strange situation, like blank rows and etc
it can misbehave in strange situation, like blank rows and etc
Thanks to @Paul_Danyliuk that with his post have helped me figuring out some part of this process, it’s absolutely nothing new or special, it’s just how i have done it
Note for codan: This process have one big technical problem, table from the cloud backup need to be updated or re-synced everytime to work, so users have to wait at least an hour to restore their backup, can we have an automation for that? plis? a button that sync every taaableeeee??? 
Also, in a more serious way, all user data are gonna be synced with every user in every doc, that’s not really privacy friendly, if we could sync just “that user” data it would be amazing, and at that point also some other filtering could be interesting 
In this way i’ve resolved not just the backup needs, but also i’ve found a good way to manage multiple version of the app, if a new version is out, an user can just export and reimport his/her data into the new app.
So, if i have multiple small communities or teams that use the app i can update it with no manual efforts, i just share the new version link (love publishing  ) that they can use after having reimported their data or if the user wants to edit the doc he can copy it and have it fully customized in seconds! (no, actually it’s more like minutes but anyway lol)
) that they can use after having reimported their data or if the user wants to edit the doc he can copy it and have it fully customized in seconds! (no, actually it’s more like minutes but anyway lol)
Ok, this is a fast version of this post, if i see that there is some interest in this i will update it with more info or photo
Thanks for reading Have a nice bakup-making