Hello community,
I’m seeking some assistance building an iterative counter for a production log.
I have two tables of data. One table, Requests, collects data from a Sheets form submitted by customers. Each request submitted by the form contains a date stamp. I’m trying to calculate a running tally based on the year in the date stamp.
Each request received in 2019 would increase the counter by 1. Until 2020, when the counter will reset to 1.
This is what I have in mind: 20190001, 20190002, … 20190439, 20200001.
I’ve scoured the forums and found some filters and count formulas, but what I’ve written tallies the total number of requests as the same number in every row. I’m hoping to show the request sequence number uniquely in each row as a display column for a product tracker.
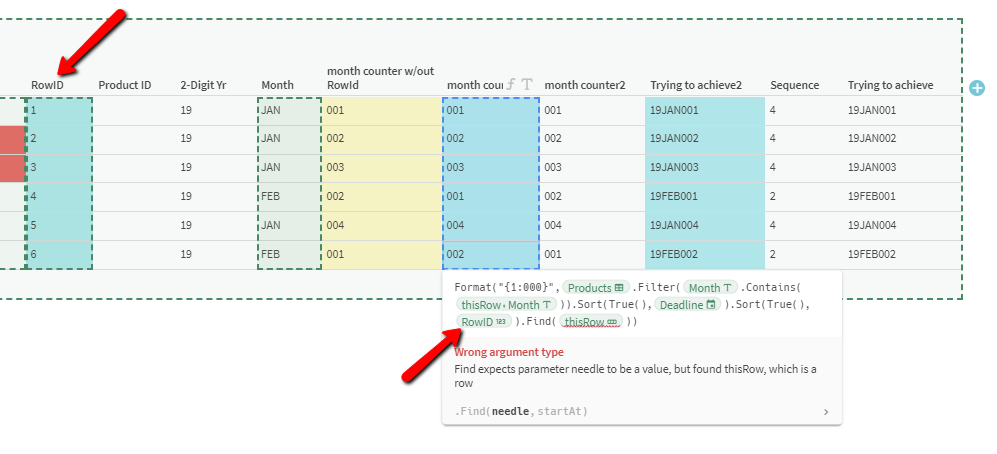
The Products table is a product tracker and operates works in a similar way as the Request table. Instead on a date stamp, I’m hoping to create product ids based on a deadline’s year and month plus an iterative counter for the deadline. Again, deadlines assigned in different months would reset the tally and iterate base on the month.
Like so: 19JAN001, 19JAN002, 19JAN003, 19FEB001, 19JAN004, 19FEB002
I’m providing an example frame to visualize what I’m hoping to achieve.
I really appreciate any help or ideas, truly, thank you!