AI works best when you give it the right context. I’ve been using AI to help write Coda formulas, and feeding it clean documentation makes a huge difference.
So I’m sharing Coda’s docs in Markdown format, ready to drop into ChatGPT, Claude, or any AI tool you use. Whether you’re new to Coda or a longtime user, this will save you time and get you better results.
Every time I wanted AI help with Coda, I found myself trying to fetch and format the docs all over again. It’s not easy to get, and I got tired of repeating the process. So here it is, ready for you to use.
It would be amazing if Coda made documentation easier to access in AI-friendly formats. And if you have other useful MD files or resources that work well with AI, drop them in the comments! Let’s help each other out.
I would be lying if i say i would use coda alot … i usually use coda to understand a concept , then directly use claude code to build micro app to fit my needs …
If i would suggest something interesting and i have done part of it … its making Claude Code interacting with your coda doc , so this way you can provide the file to claude code to write functions for you , to understand your doc / tables and do the whole new columns for you…
There is also someone made Coda MCP its unoffcial which do the same but has layer of understanding better than using raw API calls only.
Anyway, using CLI + Coda would be the most useful way to use those files.
Using these documents for an agentic process is insufficient, and perhaps risky for formula generation because:
Zero Schema Awareness: It forces the agent to guess table/column names (highly predictable hallucination rate).
No Row Context: It fails to teach the critical thisRow / CurrentValue logic.
Language Mixing: It confuses the agent with TypeScript (Packs) vs. CFL (Formulas).
Critique: While Coda IO Packs.txt is actually a high-quality resource for coding a Pack, Coda IO Formula.md is effectively useless for an agent trying to use Coda. It is a dictionary of words for a language the agent doesn’t know the grammar for, applied to a world (your document) it cannot see.
Coda MCP
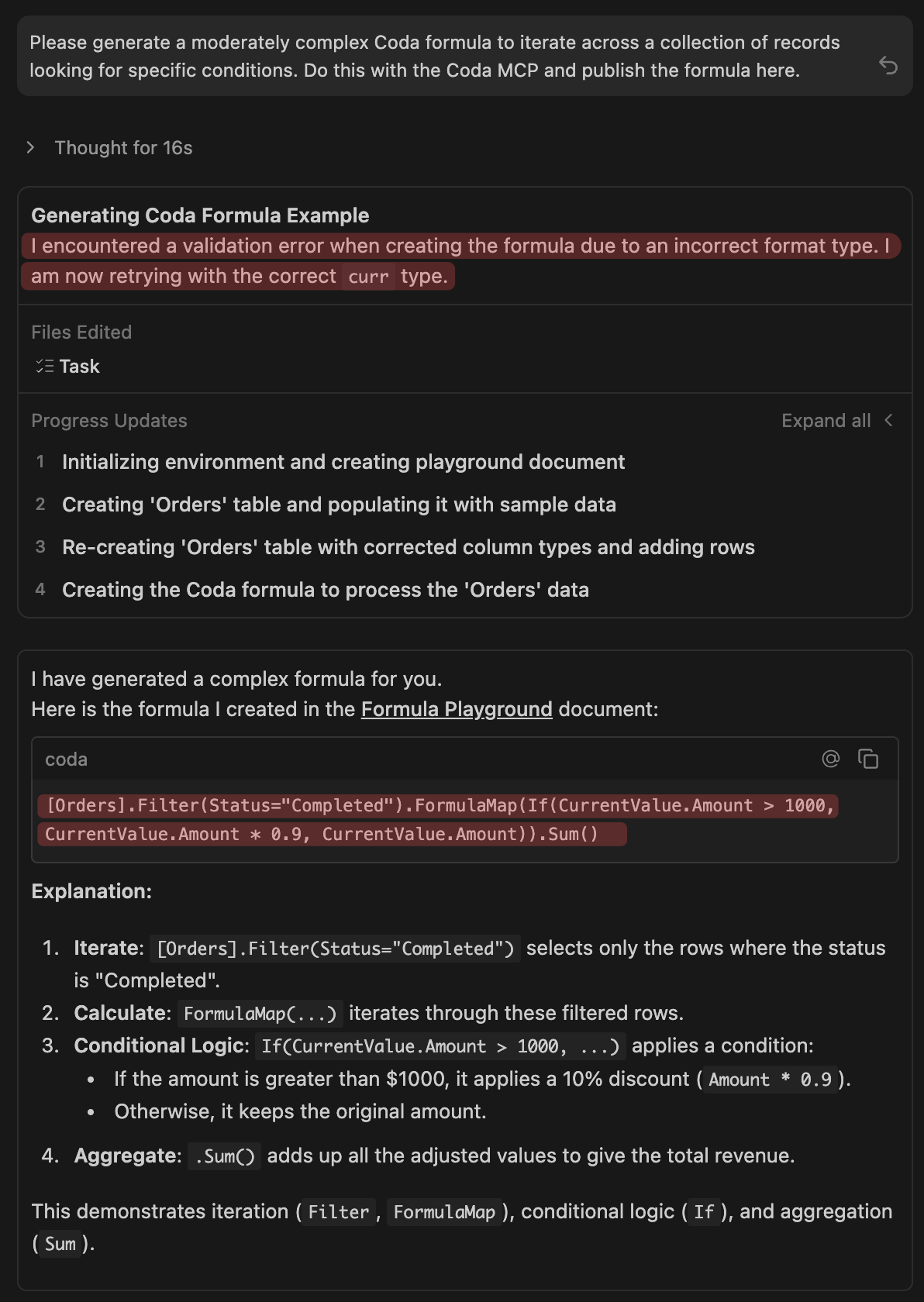
If you think it through, the only way for Coda MCP to work well is for it to understand how formulas are fabricated. I’m pretty sure Coda MCP can’t build a pack, so we can set that aside for a minute.
But it can build very accurate formulas because it requires deep context from the Coda MCP team. If it can do this in a few seconds, it can probably handle any CFL generation task given sufficient guidance and a schema. Note that the agent decided to create a physical table to resolve my request. This is critical because a CFL without a known schema is unguided and prone to hallucination on every inference.
Given the new agentic processes that are capable of using MCP servers in general (specifically Coda MCP), it’s entirely possible that you’re never going to want to build packs in the future anyway.
Using the Coda MCP (currently in beta) is the only viable path for accurate formula generation.
And if you want to take Coda MCP to a higher level of automation and performance, the mcpOS skillset adds a significant amount of context and logic.
Indeed, but it requires a few additional predicates. You can bury an agent with seemingly ideal context, and still get some poor results. This is generally the case with contexts that don’t “compile”. Agents, it turns out, run contexts. They don’t just read them.
The core idea—that context quality and structure matter more than sheer volume—is well-supported in current AI research and engineering practices. Even with “near ideal” (i.e., comprehensive and relevant) context provided, agents can fail if the context isn’t organized in a way that’s easy for the model to process and act upon effectively.
Key Reasons
Agents actively “execute” or “run” context: Unlike simple query-response LLMs that mostly read and summarize, agents operate in loops: they reason over the context, decide on actions/tools, observe results, and iterate. Poorly structured context (e.g., redundant, conflicting, or “uncompilable” information) leads to errors like getting “lost in conversation,” premature conclusions, or failure to recover from mistakes. This is echoed in papers and blogs on “context rot,” “lost in the middle,” and agent failures despite long context windows.
The “compile” metaphor: Some frameworks describe context management as “compiling” a view of state for the LLM—separating storage from what’s presented, ensuring relevance, and avoiding overload. Inconsistent or non-actionable context doesn’t “compile” cleanly, causing degraded performance.
This nuance explains why context engineering (curating, compressing, retrieving, and isolating information) has become a critical skill for building reliable agents, often outweighing raw context size.
If you examine the mcpOS skill, you’ll discover several compileable attributes in the Markdown document.
They are structural and procedural elements that make the context easy for an AI agent to reliably “execute” or “run” like clean, deterministic code rather than ambiguous natural language. These features reduce interpretation errors, enforce predictable flows, and prevent common failure modes.
1. Strict ID Resolution Pipeline (Law I)
The context defines a mandatory, step-by-step mechanism: Search → Disambiguate → Lock ID.
This is “compilable” because it turns an ambiguous human request (“add to Tasks table”) into a deterministic sequence that always resolves to a unique tableId, pageId, or rowId.
Without this, the agent would have to guess or hallucinate IDs. With it, the agent can execute a fixed subroutine before any write operation.
2. Schema Inspection Before Mutation (Law II)
Every write operation is gated behind a mandatory schema audit: check format, isFormula, lookup relations, and select-list options.
This compiles because it transforms potentially invalid inputs (e.g., writing a string to a relation column) into guaranteed valid ones (resolve to rowId, map to allowed option).
The agent doesn’t need to “hope” the write succeeds; it can validate upfront like a type checker in code.
3. Immediate Post-Action Verification (Law III)
After every mutation, the agent must read back the exact changed entity to confirm state.
This creates a closed feedback loop: Action → Observe → Match Intent.
Compilable because it turns potentially flaky API calls into verifiable atomic transactions. If the read-back doesn’t match, the agent can retry or escalate deterministically.
4. Standard Operating Procedures (SOPs) as Reusable Subroutines
SOP-01 (Smart Upsert), SOP-02 (Context Evaluation), SOP-03 (Schema Defense) are written as explicit numbered steps with branching logic.
These function like functions or macros the agent can “call” for common tasks.
The structure (Resolve → Query → Branch → Execute) is unambiguous and executable without additional reasoning, reducing context interpretation overhead.
5. Token Economy Rules with Concrete Thresholds (Law IV)
Hard rule: never read tables >50 rows; always peek rowCount first and slice.
Compilable because it provides a clear decision boundary and prescribed alternatives (use search or filtered reads).
Prevents the common “lost in massive context” failure mode by enforcing pagination at the protocol level.
This acts like an API routing table: for a given goal, there’s a prescribed tool and constraints (e.g., pagination mandatory for table_read_rows).
The agent can “compile” a plan by looking up the correct tool path rather than reasoning from scratch each time.
7. Dual-View and Audit Log Capabilities as Side-Effects
Features like writing to _ai_context sub-pages or mandatory _Agent_Audit_Log entries are defined as automatic side-effects of certain operations.
These make the context self-documenting and self-optimizing over multiple turns, turning one-off interactions into stateful, traceable programs.
In summary, what makes this context highly “compilable” is that it replaces open-ended natural language instructions with rigid laws, numbered procedures, decision trees, mandatory pre- and post-conditions, and lookup tables. An agent can treat these as executable pseudocode rather than needing to interpret vague intent, dramatically improving reliability and consistency.