Hey everyone,
Today I’m launching the OCR Pack!
It lets you read text in images and PDFs ![]()
It’s taken a lot of attempts, research, and experimenting - I’m stoked for this solution and I hope you are too!
Hey everyone,
Today I’m launching the OCR Pack!
It lets you read text in images and PDFs ![]()
It’s taken a lot of attempts, research, and experimenting - I’m stoked for this solution and I hope you are too!
So exciting! Been wanting something like this for a while
You rock!
Hi @Rickard_Abraham , this could be interesting.
Would you mind creating a video showing some use cases?
Don’t hesitate to share your story in more detail, what looks easy, rarely is.
cheers, Christiaan
I can imagine. Some late nights dialing this in I’m sure. ![]()
I assume your approach employs some good libraries as opposed to generative AI to accomplish its seemingly accurate extractions? If true, this could be an advantage because many firms are generative AI-averse and try to avoid such dependencies.
Ooh cool! I’ve been dabbling in a bit of OCR stuff lately too. What do you use under the hood? Tesseract?
If this does what I hope it does, it’ll be a real game changer. Thanks!
Thanks everyone for showing such great interest!
I’m using Google’s powerful Document AI and I’m amazed at how quick and accurate it is.
Before discovering this fantastic solution, I experimented with various Python packages on both GPU-less servers and GPU-enabled servers.
If you have any requests for this pack then please let me know!
Implemented better error messages!
![]()
![]()
![]()

Privacy and security
Lowered price to $5 per doc maker ![]()
Someone seems to be hitting the api maliciously, had to disable this pack for the time being, sorry about any inconvenience. Happy to refund if you contact me
Had hoped not have to implement a long-term rate limit. Coda has a built-in rate limit but the time limit is 60 seconds, which I’m afraid isn’t long enough:
Is there a way to implement this just in my doc without a pak? …and not for sharing? Happy to pay for your expertise. ![]() — I am just looking for a quicker way to do receipt data entry from a scanned receipt.
— I am just looking for a quicker way to do receipt data entry from a scanned receipt.
I’m glad you’re reaching out! I’m sure I can revive this privately for you ![]()
In the big picture I am striving towards a better permanent public solution for the rate limiting issue, but that will take a while.
Lets continue this conversation in dms ![]()
I hope this will fix the issue of the server being vulnerable to malicious attacks. In order to deliver the best OCR experience possible to all Coda users I have my own credit card hooked up to use Google’s API. The attack 3 months ago costed me around $80 before I caught it, could’ve been much worse ^^
@Rickard_Abraham In you example, you have the produce invoice as one of the PDF’s, which is my exact use case. I’m curious if you have a suggestion to how to use the extracted text, whether through AI or a formula, to capture the price of specific items on the invoice? The way it is extracted in just one column without any structure stumps me at the moment. My dream would be to scan the invoice with the OCR pack and then have the price for those produce items be automatically updated in a separate table.
Great question @Ben_Peine!
It’s attempting to return the result in a natural reading order, meaning that in most cases it should be possible to construct invoice items thanks to the order (with or without AI).
Beyond this we’re looking at specialized invoice processors, which would require sample invoices provided from you to train it to fit your needs
I’ve discussed the pricing model with @Christiaan_Huizer which resulted in me now striving towards an external pre/post paid system for extended OCR use!
This would be required before I could provide a specialized processor as they are much more expensive than the general processor I’m currently providing (still talking less than a few cents per page!)
I’ll keep you updated here with my progress, and please let me know what you think ![]()
Scan(Media)Lets you mix PDFs and Images ![]()
Deprecates the original ScanImages and ScanPDFs formulas.
Each token (message me to get yours!) has 1000 monthly credits.
Each page and image scan costs 1 credit
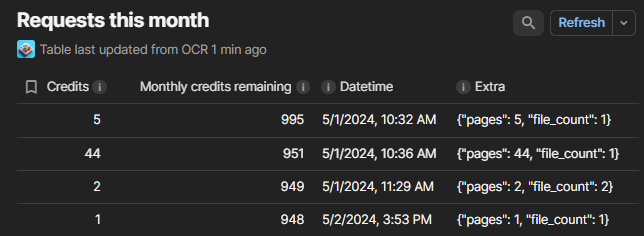
See each request you’ve made this month, how many credits it took, and how many remains
Get a simple number for how many credits you have left this month
Original and default output
Use this option to get a list of texts.
Coda currently has a 85 kB limit when writing to a cell, each text will be below this limit, letting you create rows without worrying.
Concatenate() the rows afterwards for the complete scan result
Get a temporary txt file URL which you can ingest into a File column to store it permanently in Coda.
Name the file with the optional 3:rd filename parameter.
To expose the actual text within this file, use the new ReadTextFile() formula (formulaic columns don’t have the same 85 kB limit)
BuyCreditsUrl() formula (200 credits per dollar)Requests sync table to include refills:great job @Rickard_Abraham ,
looking forward testing it any time soon!
cheers, christiaan