The Archetyper is an assessment for facilitators to discover their facilitation archetype. The initial idea was that all the “intelligence” for delivering the results would be done on the form platform using conditional logic.
After tinkering with tally back and forth, I created a form where the user gets the answer as soon as they finish answering the questions. However, the answer was not sent by email to the user. So, they had no way of saving the outcome. Besides, I wanted specific usage statistics that the tally did not provide me.
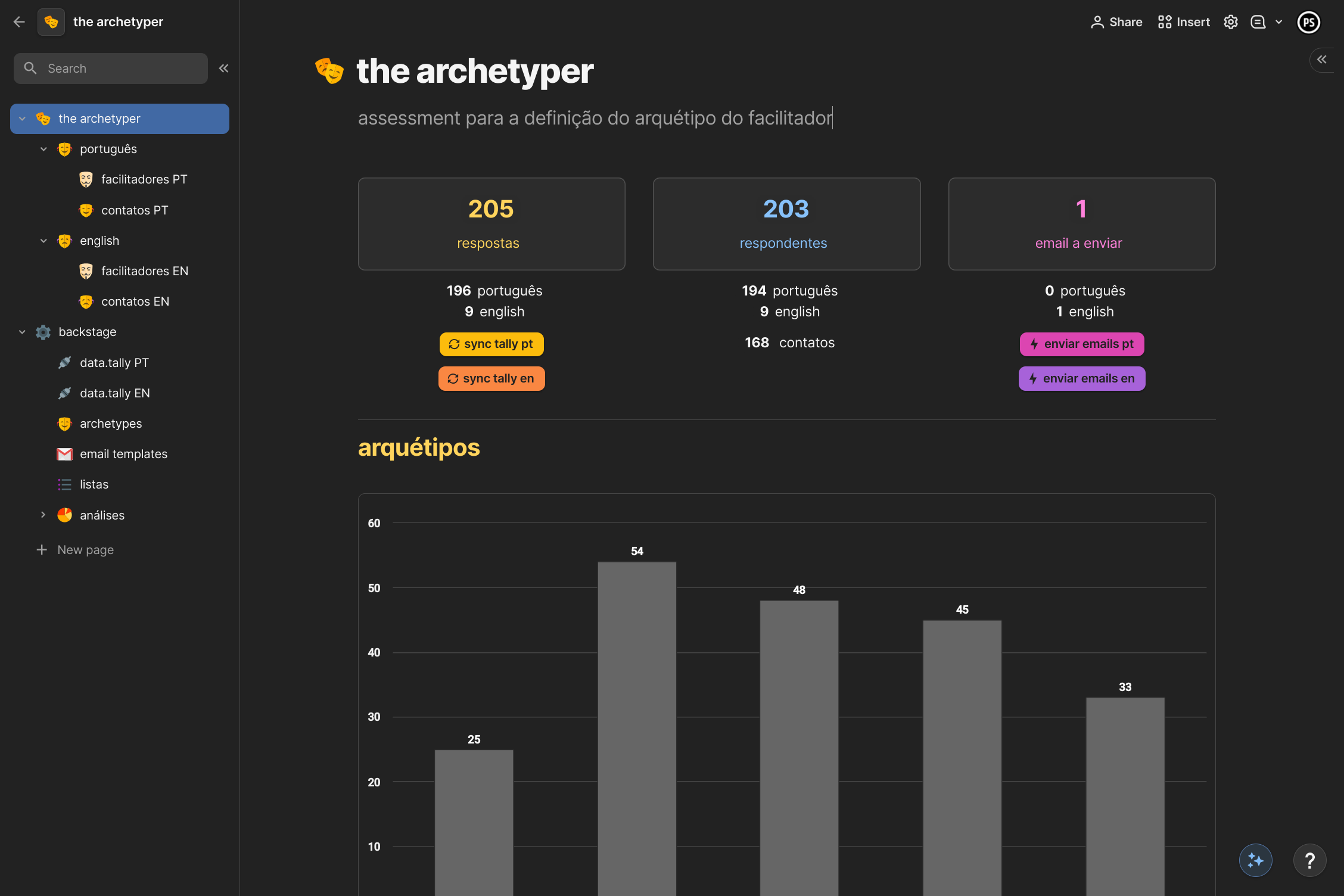
To solve both issues, I created a “backend” for the assessment on the coda. The responses to the form on tally are sent to coda through the integration between the tools. From the entry of new records, the coda triggers an email with the user’s response (through automation) and summarizes the responses in a dashboard that shows:
the number of responses
the number of unique respondents
how many emails should be sent
the number of each archetype
the overall score in focus and approach
how many respondents work in companies or as freelancers
the number of respondents in each range of experience with facilitation (1-5)
Initially, the assessment was done in Portuguese. A new challenge arose when I wanted to publish an English version - which was built from a new translated form on tally. Duplicating the backend would be an easy solution, but I would not have a unified dashboard with the responses in Portuguese and English. So, it took me a few more days to wrap up my brain to generate suitable data from two different tables (one coming from each form).
Today, I finally launched the English version. The backend is working beautifully, and the whole workflow of response, registration, and email sending is automated. The Archetyper does not need any interference from me to work.
thanks, bill!
I started to implement some AI here and there.
but since the coda 4.0 came, and they started to count AI credits, it became useless.
the credits are drained at such a speed with so little things that something that I thought could be a game changer, the way it is now, is just a gimmick. what a shame.
I did a test yesterday and a very simple task, in one row, based on few information, consumed 64 credits. I hope it is a bug. otherwise, coda AI is useless in the real world.
my account has 1000 credits per month. I can’t implement anything with just so few credits and the impossibility of buying more. neither the 3000 credits of the team plan is closer to enough. and I don’t think adding new ghost doc makers to my single-person team is a good solution.
to use AI in a workflow, we need to get in well-tuned prompts. and this takes a lot of tests and experiments that will drain your credits before you can put them into action. at least, in my experience. are you using AI for real?
Yes, but I’ve reframed all internal work with Coda using Coda Packs to integrate with LLMs. This was a painful change. The week that 4.0 was launched I was left with no choice to keep the AI “lights” on.
that’s it! from ideation to validation, there is a long way of spending credits before effective implementation.
I had the same issues after de 4.0 launch. thankfully, I could solve the most critical ones with formulas. but, I have a lot of experiments that I can not go futher. what means a lot of time on the throwed away.
I shared this with the Codans long ago. I explained in vivid detail the economic impact token-tracking would have on Makers and users. And I went even deeper with this article.
Credits and tokens are a poor measure of GPU consumption. They might be useful in back-office analytics, but consumers are intolerant of arbitrary conversion rates.
Ask any energy consumer what they think 11.389 cents per kilowatt hour means.
Imagine if you had an ointment for sore knees that comes with an eyedropper applicator. The price indicated on the package is $0.0000238 for a light dropper squeeze. But a firm squeeze of the medicine is $0.000182. How would consumers react to this?
No consumer could easily do the math well enough to feel safe about purchasing this product. Every drop of the ointment would need to be pure magic, or the pharmacist would need to find another approach. Ergo, for generative AI to be sold with a similar pricing model, it would have to be pure magic and flawless. Ahem…
While I must credit @DavidK for providing some education about the inference costs, until they find a better way, they should constrain no users, else, rebounding will be almost impossible.