Team,
Is this a limitation of Coda? Trying to copy and paste ~1m rows from a CSV and it’s erroring out.
Team,
Is this a limitation of Coda? Trying to copy and paste ~1m rows from a CSV and it’s erroring out.
Have you tried doing it in chunks?
I have not heard of anybody using a million rows in Coda, so it might be too large.
What is the error message that you are getting?
Can you successfully post a subset of rows?
Also try the /csv command instead of copy pasting
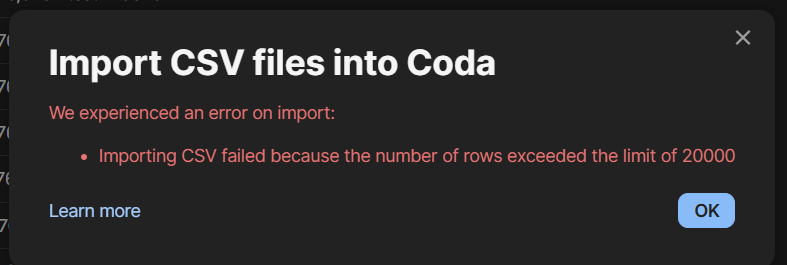
That seems to cap out at 20k. Doesn’t look like there’s an upsert option to import in chunks. It does look like I can paste it in chunks of 100k so that could work. Thank you.
In my experience doc performance becomes quite poor beyond 25k rows in a doc even when those rows are not that computationally heavy. So I would think you would definitely not be able to run a Coda doc with 1M rows even if you do manage to import then.
On the annual call with Shishir last week Lane spoke about working on allowing for much large datasets this year, but it’s definitely not launched yet
@Amish_Noorali , just to step in and as @Bell_Arden mentioned, progress is expected this year, but today 100K feels like the max I have seen demonstrated.
When you notice that coda puts limits on pack tables (10K) and CSV import 20K, you maybe can imagine that the coda ambition today is closer to these numbers then to the 1M you have in mind. Who knows what the future will bring, I am hopeful, but 1M is quite a stretch from what we have today
Cheers, Christaan
The most I’ve done personally is ~50k in one table and about ~70k in the entire document. The doc was temperamental but I got it working after some trial and error.
I’d be pleasantly surprised if you could do 1M. Good luck!
Thanks everyone for the feedback. We are exploring Coda as our corporate project management tool and roll-up reporting is a key objective but also template-based structure - meaning, if we have one master template, we want to be able to deploy that to all projects as changes are made to it. We don’t want our PMs to manage that - they should only manage the content.
Ballpark, we’re looking at 1000 projects, 100 tasks each, 10 budget items for each task…so 1k project rows, 100k task rows, and 1m budget items.
I created some dummy pages with tables with ~200k rows each.
And a summary view to do a simple count on each page
Performance seems okay but obviously this isn’t a realistic test since in a practical use-case, there will be calculations.
I’m a fan of Coda and it’s extensibility but we do need a scalable solution.
Ballpark, we’re looking at 1000 projects, 100 tasks each, 10 budget items for each task…so 1k project rows, 100k task rows, and 1m budget items.
would you be needing all this data all at once? i.e. active and query it ?
is the data text form? or has objects (files etc)?
if you’re open to archiving but having the data still accessible, this maybe a possible solution -

cheers!
Mel
Hi @Melanie_Teh
No, we don’t need to view all the data at once - there’s no practical use-case where a user would scroll throw millions of rows. However, the data structure does matter in order to manage this at scale and also for reporting purposes. Our structure is relatively simple:
The reason we can’t/don’t think we can use subtables is because of maintenance. We have a master template for projects and project tasks. We anticipate updating these often and want to ‘push’ them to every project/project task row. I don’t know of a way to ‘push’ these master templates and keep them in-sync without losing existing data; we’re currently using canvas to keep that in-sync.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.