Thank you @Ayuba_Audu for this extensive feedback, much appreciated! ![]()
this communication is exemplary.
a clear statement of the range of use-cases being targeted.
explanation of the issues preventing a simple quick deploy.
reasoned direction and probable sequence of feature releases.
sets great expectations, and reassures us all of the strategy… so we keep the faith and have patience.
but also makes it clear that predicting timelines is not possible.
THIS is the kind of update we need more of!
well done @Ayuba_Audu and team. take a bow. accept our applause.
max
7 Likes
Thank you @Ayuba_Audu for your extensive feedback. My takeaway is you have a clear picture of the needs and the challenges. Your explanation of the steps needed to reach the goal makes sense. However;
This sounds like you’re still trying to come up with a solution and nothing is being build yet. “We plan to make…” “We eventually plan to allow…” “We will be working on…” AKA check back in a year or so.
On the upside, two-way Cross doc is apparently being worked on actively which would be a great help.
I’ll return to the sidelines and impatiently wait for updates ![]()
1 Like
thanks @Ayuba_Audu for the update.
It is the first time that I remember that we see ambitions in this realm clearly expressed in the community and I do appreciate this a lot. Two way sync is an often asked for request and touches many Coda fundamentals.
I hope and expect to read your regular updates in the community. I understand that this may not be easy for the Coda team, but a good challenge never is.
Cheers, Christiaan
1 Like
Thanks Ayuba and Coda for providing some transparency here, this can be a delicate dance. I for one appreciate even the attempt to do so, the clear messaging and expectations in this post is a cherry on top for me ![]() .
.
Thank you @Ayuba_Audu ,
This is precisely the kind of explicit, context rich, and community considered communication we have all been hoping for, much appreciated.
And most importantly it gives me the confidence to further deploy Coda into my org and to spread the word more confidently.
My only comment being that it is so fundamentally important to Coda’s development that I feel it should have (or should still be given) a lot more exposure (I’m well invested in Coda and the community but would’ve missed this if @Christiaan_Huizer had not emailed me to let me know about it). So I’d strongly suggest including a summary of this in the monthly emails, or a Coda blog post or at the least a seperate ‘news from Coda’ post.
4 Likes
@Ayuba_Audu – echoing what other said here. Thank you so much for the update, the clarity, and laying out the direction.
I am glad and excited to hear about the two-way sync. I hope it comes with column lock so that folks can have best-practices around where source data is being generated for specific columns and where it is being consumed as context.
Thank you!!
-A
Thanks! I really enjoyed reading about the process and goals.
While these are desperately needed functionalities, I have begun to recognize the sharing horizon is wafting up mirage-like ripples affecting my vision of what it means to “share” parts of documents and data. I fear that by the time you sort out the deeply complex machinery necessary to ostensibly make copies of shared resources, a different approach will become obvious because competitors will already be doing it.
I have seen glimpses representing the future of sharing in various communities and it has changed my perspective concerning logical reflections of information. A good way to think about this challenge is to embrace the nature of data science. We use aggregations to distill and reflect upon information sets that are often so large there is no alternative approach. Data science has helped us master the art of aggregation to tell stories.
Why aren’t we applying the same techniques to documents?
I think the short answer is the architectural limitations. As brilliant as Coda must be under the covers, it is [apparently] not prepared for a future where data-sciency-like aggregations could occur. This may explain why we have no API access to document texts. It also [perhaps] explains why we have no formulaic access to texts or the DOM. Feel free to enlighten me if I’m misstating this intimation.
And then, there’s the elephant in the room. AGI.
Sharing document slices or data filtered by human-crafted queries through discrete UI settings, configurations and other guided programmatic nudging, may be completely unnecessary. AI is most certainly how this will be achieved in the very near future, possibly next week. ![]()
Imagine creating a briefing summation that rolls up three Coda documents and presents the state of the information in a shared report with executives. The report includes high-level charts based on data tables in the documents and may even include a chat feature that allows users to ask questions not specifically expressed in the report aggregation.
This is how AI will revolutionize work. Carving off slices of information for specific personas and use cases will require an abstraction that can only be achieved [practically] through AGI. This vision is not a wild idea; it is already being demonstrated at Microsoft using OpenAI.
We can’t “Pack” our way out of this architectural cul-de-sac.
It will require an underlying information architecture that is sensitive to such “aggregations”. Pandas, for example, is the architecture data scientists use to magically distill and separate signal from noise. There is no equivalent of Pandas in Coda, or in any document system and this forces us to cache-forward our document content into a Pandas-like design pattern to make this possible.
As Microsoft has done so well, I can also demonstrate what I presented in the briefing summation vision using PaLM 2 and a collection of Google Docs. Sadly, I cannot do so in Coda.
2 Likes
Sorry for the late reply
What I find extremely useful is to pull into 1 view multiple Google Sheets, which is then shared with the specific people with specific permissions. In this way I do not have to click around to find 30 people’s travel reimbursement sheets, but I have one view to work with it. Huge step towards page-level permissions in a way that I keep using what is built in Google Sheet but already within Coda.
The specific use case of mine is to bring travel reimbursment sheets of participants into 1 view (Doc) and this I need for each project and I have 15 projects at least annually (or more).
So now what I do is doing the same sequence of clicking for the 30 participants in each project. It would be awesome if I could pull from a table or a Google Sheet the links I collect for each travel reimbursement sheets and then it creates automatically pages with full-embed with the Gsheet links. taddammm!
Thanks a lot for all you efforts Coda is amazing!
Many thanks for sharing the details and examples @Tamas_Mahner! No apologies needed as feedback like this will help us as we prioritize future updates.
1 Like

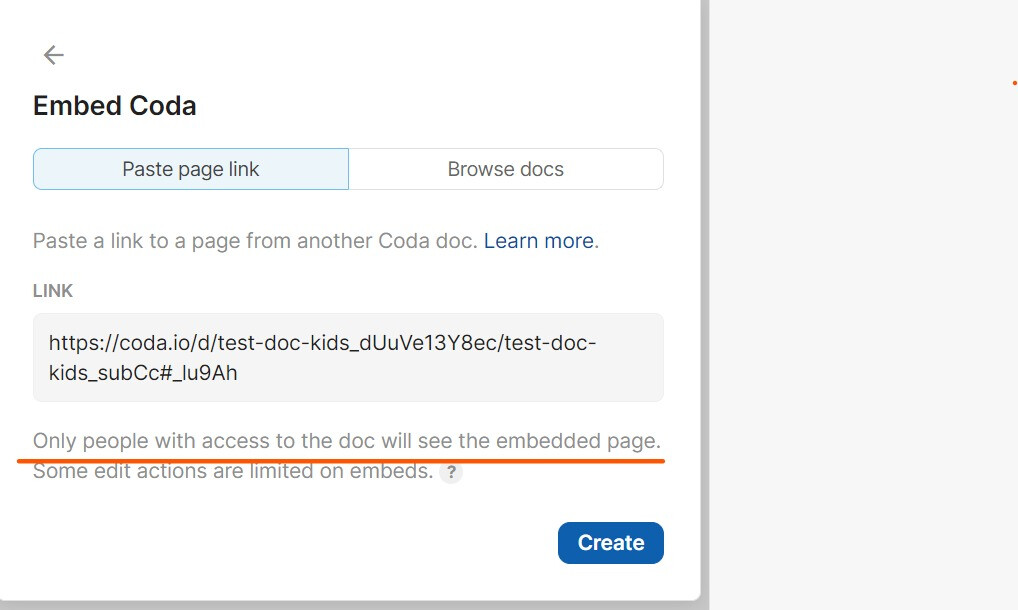
We have another exciting update to full-page embeds — embeds of Coda pages are now editable! Coda page embeds will now be presented with your same level of access as the doc you’re embedding from, so in addition to having all your information together, you’ll also be able to make changes without having to open another doc. Your existing Coda page embeds should update with no changes required and new ones will automatically inherit your access level. Note that some edit actions are limited on embeds. Editors can:
- Use buttons, controls & forms
- Change table values
- Add and delete rows
- Edit page text
Additionally, this update introduces compatibility mode, an update to the “force” parameter which is now supported for both canvas and page embeds. You may need to toggle compatibility mode on from the embed options menu to successfully embed certain links.
Thanks for your continued feedback as we improve and expand Coda’s content sharing capabilities!
15 Likes
![]() everyone,
everyone,
As Gleb shared above, we’ve now made Coda page embeds editable! This is the first step in the path toward granular content sharing that I outlined in my previous response. We hope this will provide a more seamless experience for you all and broaden the range of use cases you can leverage full-page embeds for.
As mentioned, the next step in Coda’s content sharing evolution will be to allow secure embedding of a single page in such a way that no other parts of the embedded doc are accessible. We’ll continue to reference your feedback and keep you in the loop as this takes shape — many thanks as always for your insights!
15 Likes
Hi @Ayuba_Audu ,
First of all, thank you for the clear communication about this topic here and elsewhere. Your efforts have not gone unnoticed ![]() .
.
I think the following step will be the crux of the problem - probably quite a technical feat to pull off:
allow secure embedding of a single page in such a way that no other parts of the embedded doc are accessible
What I hope this means:
-
Formulas created in SourceDoc/SharedPage continue to be executed in the ‘namespace’ of SourceDoc even when run from TargetDoc/SharedPaged, but with the User() formula returning the TargetDoc user.
-
The above extends to filtering formulas, so that I can prepare a filtered view in SourceDoc/SharedPage that returns different rows for different users, and have peace of mind that only the resulting rows will be accessible in TargetDoc, even to the clever users who know how to dig into Chrome’s developer tools and browse the page’s source.
-
Formulas in TargetDoc/SomeOtherPage can still reference objects in TargetDoc/SharedPage, but only its loaded content.
Can you tell us, without making promises, whether this is your general direction of travel?
Honestly, if you guys can pull this off then I will be one overjoyed customer. I’m no engineer, but I guess that getting it done would almost certainly involve switching to a model where calculations of the shared page are run on your servers instead of the browser…
To help get this over the line, here are some compromises I would be happy to make in TargetDoc/SharedPage:
- It’s ok if it inherits locking settings from SourceDoc and these can’t be changed
- It’s ok if I can only Use buttons, change table values, add/delete rows. No need to Edit page text, and no need to be able to write any new formulas.
- It’s ok if new @ mentions only reference the SourceDoc namespace.
Happy to discuss this separately if this is not the right venue for this level of detail.
4 Likes
Appreciate the kind words and your detailed feedback — including compromises, @Nad! ![]()
I can say that is the general direction. While there are more considerations, you’ve captured some of the concerns we’d want to address.
3 Likes
I am very excited about the editable page embeds and the upcoming sharing of single pages without access to the other parts of the embedded doc.
Does this mean that we will have the ability to embed pages into another doc and let users interact with them without granting them access to the original doc?
We have created a central repository for all of our information but would like an easy way to create team-specific documents that give users access to interact with the information that they need without giving them access to the full repository.
3 Likes
We’re excited as well, @Tracy_Horner!
Yes, they’ll have access to only the page you’re embedding and not the entire doc you’re embedding from.
In this case, one pattern we’ve seen from customers which might help short term is to create the team specific information in the team hubs / docs, then embed into the central repository. This way you don’t need to give access to the central repository, while still having a central place for all the content.
1 Like
hi @Tracy_Horner ,
I was as curious as you and tested it. Permissions need to be equal on two sides to get access to the embedded doc. The most confusing is when you embed a doc and people start to aks for permission to the source doc, but that you cannot give. In the below ‘see’ means see the content of the page, the page is visible in the doc.
as @Ayuba_Audu suggested, there are work arounds, but I’d rather avoid them. I assume Coda will solve this issue by the end of the summer, so I wait for that.
Cheers, Christiaan
3 Likes
This is great. I’ve hit a wall around needing editing of a table / page without being signed in. I hope this is part of your technical planning and I am sure it is as it is mentioned throughout the community.
1 Like
Hello @Gleb_Posobin , @coda_hq,
I have been doing some testing with embeds and although my main concern is the necessity to share both the original and the document with the embeds, this is a nice step forwards and certainly serves some use cases.
I have run into 2 things that might need to your attention while developing the next steps, I am writing this post to share them with you. This is about the doc with the embedded page(s).
-
I have an embedded page with a table with a related column (to a person table). Upon hoovering over the person objects, I can expand the object and open a modal to these objects (persons in my case). So far so good, but at the top of the modal there is a link to the person table - and this table is not part of this specific doc. Upon clicking on the table link, the original document is opened and the table is exposed. Even though I am aware of the fact that the user has access to both the original doc and the doc with the embeds, I made the doc with the embeds to separate things and to nog have users (accidently) end up in the main doc.
I hope this can be addressed. -
we have had issues with using some docs on Apple mobile phones, including the newest ones: the docs crash immediately or within seconds of opening. This is while using chrome, safari or the app. It seems to only happen with seriously big docs. I had the hope that with embedding only a few pages, this problem would be solved, but is it not: I am under the impression that the full (original) doc is loaded even though only a few pages are embedded. On Android we don’t have this problem, perhaps it will solve itself with a future ios update, but if Coda can prevent downloading the entire doc it would probably improve things too.
Thanks for your attention,
Greetings, Joost
2 Likes
Hey bill,
I’m just reading this massive thread but I quickly came up with something that could work reading into your problem?
(1) Coda has an API you can call to get your data from within tables inside of your doc
(2) You can structure your data in whatever way you want… as long as you know how the data looks like
(3) Store all the data in a data warehouse. Aggregate it with other data sources if you want
(4) You can run aggregate functions (Chatgpt, NLP) on your data warehouse
Would this be a solution to what you’re looking for? Albeit you’d have to natively build this xD